Functional Programming with Python for People Without Time

Functional programming for the purpose of this article (and I claim — for the purpose of most of your day to day work), is all about building pipelines and moving data through those pipelines.
Two constructs that you probably already heard of make up much of our pipeline oriented work: these are map and reduce.
As an appetizer, here’s a puzzle — pick all the first names from a list of people, and print them joined by a comma (“,”). Make the resulting code clear to read and as minimal as possible. Let your friends try, too.
people = [
{
'first_name': 'Bruce',
'last_name': 'Wayne'
},
{
'first_name': 'Joker',
'last_name': ''
}
]Also, take a moment and try it imperatively.
Let’s do this with map and reduce only.
first_names = map(lambda person: person['first_name'], people)
joined_names = reduce(lambda acc, name: acc + "," + name, first_names)
print("{}".format(joined_names))# Bruce,Joker
Let’s get rid of ephemeral variable first_names and joined_names which just stand there and do nothing but serve as a fancy temporary bag of values (by substitution):
joined_names = reduce(
lambda acc, name: acc + "," + name,
map(lambda person: person['first_name'], people))
print("{}".format(joined_names))# Bruce,Joker
And once again:
print("{}".format(reduce(
lambda acc, name: acc + "," + name,
map(lambda person: person['first_name'], people))))# Bruce,Joker
Super hard to read, and you’re already making the conclusion that functional programming goes against all craftsmanship principles in software, that it’s not maintainable and that all functional code lives somewhere in the academy in one of their ivory towers.
Well, it’s not true; and this is the point where most people fall off, marks “never go there again” and “functional programming is for stuckups”.
Let’s reverse engineer this process. Taking a couple steps back, we can see that we have the concepts of a first name extractor:
lambda person: person.first_nameAnd we have a kind of a joiner of things:
lambda acc, name: acc + "," nameBut we can make these generic, because there’s nothing special about a comma being a separator and a first name field:
def joiner(sep):
return lambda acc, name: acc + sep + name
def extractor(field):
return lambda person: person[field]If you’re thinking — excessive use of lambdas - that's the Pythonic anti-functional-language mindset rearing its head, hopefully we'll break through that soon. Any way, refactoring to incorporate our latest moves, we now come at this:
print("{}".format(reduce(joiner(","), map(extractor('first_name'), people))))# Bruce,Joker
You read this inside out, right? We first look at print, then format, then reduce, and realize that we don't know enough, and dig down through the parens until we hit the core - extractor, backed by map (keep in mind extractor is invoked on 'first_name' but then returns a function which map is happy to take).
We understand that we map over people, giving back a new list, which reduce takes, and joins. While this is fun as a puzzle, it can be tricky to read once we add some more map/reduce steps.
To deal with these problems generically, we need to build a pipeline of functions that go over our data — or using the correct analogy — a pipeline through which our data flows. This is one of the areas where functional programming shines.
Here’s how we solve that puzzle properly:
print("{}".format(
pipe(people,
map(get_in(['first_name'])),
reduce(joiner(","))))
)Our pipe is built out of functions (pipe, map, reduce) that in turn are built out of yet more functions (get_in, join), and then some primitives (['first_name'], ",").
There’s nothing in here that forces you to go to a special object oriented programming school for. No inheritence, metaclasses, metaprogramming, abstract classes, mixins, and other friends.
Just functions and primitives.
In addition, this code is parallelizeable by default (just swap map with a pmap), have zero side-effects or internal state (no variables that it maintains, so less bugs), and is testable with snapshots (give it input, expect output). And that means no concurrency problems or race conditions and mocking and test rig school to go to either.
The functions get_in, join, and pipe come directly from toolz, a functional programming toolkit for Python. map and reduce come from toolz as well (they come standard from Python too), but notice everything comes in its curried form.
Which means that when we made our extractor and joiner, we received some “set up” variables, such as a separator (in the case of joiner) and a field to extract (in the case of extractor) and returned functions that were “configured” to perform with these variables.
In the more generalized sense, we created a curried version of the functions we used, and if we want to save some manual work it looks like this, using @curry from toolz:
@curry
def extractor(field, person):
return person[field]Which behaves like this:
extract_with_field = extractor('first_name')
# returns a _function_ that takes a person
# and will always extract based on the field 'first_name'
# (because it has it in its tummy)
extract_with_field({'first_name': 'Bruce', 'last_name': 'Wayne'})# 'Bruce'
In this case currying allows us to capture (or cache) a behavior of a function like extractor at different times for different purposes; or more specifically extracting different fields:
get_first_name = extractor('first_name')
get_last_name = extractor('last_name')Some would say we built a couple accessors up there.
Let’s come to a full stop here. How different is all of this from object oriented programming?
Let’s see how we would have built our extractor - for illustrative purposes we'll use ES6 (Using Javascript for OOP code just to be more strict and completely separate the different approaches for the reader’s convenience):
class Extractor {
constructor(field){
this.field = field
}
extract(person){
return person[this.field]
}
}And to invoke it:
extractor = new Extractor('first_name')
people.map(person => extractor.extract(person))If you’re thinking — it’s not too bad; at least, not too impressive to call in a whole army of functional programming operators and compose those in the voodo that is pipes and maps and currying - then you would be right.
This Extractor thing is the command pattern in disguise. Here is Extractor again as a command, with the standard execute method coming from an interface being overrided:
class Extractor extends Command {
constructor(field){
this.field = field
}
execute(person){
return person[this.field]
}
}And now if we have a list of commands, we can proudly declare that don’t care what they are, but we only care what they do:
cmds = [
extract,
join
]
cmds.each(cmd => cmd.execute(subject))Behold, a pipeline. We can build pipelines in object oriented programming! and it takes away the edge from the “everything is a pipeline and functional programming is solving pipelines” argument we made earlier, yay! nothing new to learn!.
Cracks in the Ice
We ended the previous part with stating that with a good measure of abstraction, functional programming doesn’t offer a considerable advantage over the “traditional” way of design, object oriented. It’s a lie.
Let’s start with this. With object oriented design we can abstract and build everything that functional programming offers. In fact, taking our command pattern example into account, that’s how Java’s implements lambda expressions.
That’s a particularily good example, because Java is known for its never-break-compatibility approach; it means that what ever Java is going to do to add in lambdas, they are going to use something that’s already there — and they did — anonymous classes were what backed lambdas in Java.
But here’s where this crystal-clear-perfect argument cracks. In our pipeline example above with our Executors — how do you feed in the output of one executor as the input for the next one? well, you have to build that infrastructure.
With functional programming, those abstractions are not abstractions that you have to custom build. They’re part of the language, mindset, and ecosystem. Generically speaking — it’s all about impedence mismatch and leaky abstractions and when it comes to data and functions; there’s no mismatch because it’s built up from the core.
The thesis is — that to build a functional programming approach over a an object-oriented playground — is going to crash and burn at one point or another: be it bad modeling of abstractions, performance problems, bad developer ergonomics, and the worst — wrong mindset.
Minimal Surface Areas
Being able to model problems and solutions in a functional way, transcends above traditional abstraction; the object-oriented approach, in comparison, is crude, inefficient and prone to maintenance problems.
To understand why, let’s answer the following. What are the chances for this class to fail?
class Billing {
compute_address()
billing_address()
contact_info(user)
transaction_holder(holder_id)
as_string()
save()
update()
get(id)
}Assuming we have all of the past error data in our Splunks and JIRAs, let’s pour everything onto a spreadsheet, and assign a probability to fail computed based on the past year to each method:
class Billing {
compute_address()
// 0.01 (someone had a typo)
billing_address()
// 0.01 (someone got the wrong address)
contact_info(user)
// 0.05 (user has a 0.02 failure rate + computation in contact_info)
transaction_holder(holder_id)
// 0.08 (does I/O)
as_string()
// 0.01 (someone misrepresented it)
save()
// 0.08 (does I/O)
update()
// 0.08 (does I/O)
get(id)
// 0.08 (does I/O)
}There’s a 40% chance that this code will fail at some point in the next year (for the nitpickers — assuming this code runs independently on different machines, in parallel, of course — and we’re showing just part of the codebase where all probabilities ultimately end up as 1.0):
(p(a) or p(b) = p(a+b))
0.08 + 0.08 + 0.08 + 0.01 + 0.08 + 0.05 + 0.01 + 0.01
-> 0.4While the numbers are not important (and they’re not real, remember?), nor the story of a Billing class that failed at this and that probabilities over the last year, what is important is the fact that — the more methods we had, the more chances we had to fail.
And not only that: any class that interfaces with Billing is mating its own failure rate with that dreadful number of 0.4. This is the concept of how large interfaces make up a large surface area to commit against which makes things brittle.
The solution is obvious, if I’m a User class and I need to interface with Billing I want to take a subset of Billing's interface. Maybe only that subset that is stable?
Functional programming educate for minimalistic, compact ideas, that will push you to create small area interfaces, and so you’ll typically have many small concepts rather than a big-design-upfront abstractions in form of objects and hierarchies.
Finding Your Path in a Functional World
If you tried taking up functional programming on your own, you probably know this feeling: there seems to be something everyone knows but you don’t. There’s some kind of alchemy of functions and popular operators (such as pipe, lift, and mapcat) and types (such as Maybe) that everyone seems to "get" but you don't.
What you need to remember is: for now — that’s OK. It’s OK because we’re going to map the reasons for why it happens (that’s half the battle!).
It’s Got Math Roots
There’s a ton of mathematically-oriented theories around it, an amount fifty years of research have allowed to accumulate. There are plenty of theories and proofs from mathematics applied directly to functional programming and it’s not so easy to digest without an appropriate time investment both in the history of such an academic topic and in its current form. Category theory is one interesting topic; and it’s not trivial to catch up with if all you’re interested in is building software.
It’s Language + Abstraction
There’s actually two major schools of thought in the functional programming world — the ML statically-typed-backed-by-category-theory-and-fancy-type-systems school and the LISP dynamically-typed-code-is-data-we’re-in-the-60s-so-lighten-up school. There’s overlap in some constructs (e.g. we’ve seen map, reduce) but a strong difference in mindset (types vs no types).
The popular claim is, like in the OOP world, that strong types — especially in functional languages — are critical for large codebase maintenance since there are so many small functions. The difference between OOP types and FP types is that the latter are extremely thought out and that the same core types and thinking will follow you in most ML-family language.
In other words, it’s like saying that when OOP was born, it was also born with the Gang-of-Four design patterns baked into it’s core as its backing theory of thought (outside of types and inheritence and methods etc.), and every implemented OOP language included these patterns and abstractions by default for you to take advantage of, and that these patterns were bullet-proofed by centuries of research. But that can already never be correct — the Singleton pattern is by now widely recognized as an anti-pattern, and GoF authors said they would remove it, if only they could go back in time.
That Purity Thing
There are largely two approaches a functional language need to pick from. These are the “pure” — no side-effects, and the “impure” (or maybe “pragmatic”) approaches. Where we say a language is functional and pure if a function is like a math function — it gets input and produces output and if you run it many times over — everything will be predictable. Pure functional programming languages make life super involved when building software, in exchange for very sound production software.
The Pragmatic Way
The good news is that there is a renaissance in the functional-programming world, in the shape of sound typing like Flow and programming languages like ES6 (Javascript) and Reason and libraries like Underscore.js which started an arms race that produced lodash, toolz and more, all of which are taking in a good chunk of the functional programming mindset, arguably because of extreme paradigm shift React, Redux, and the surrounding ecosystem made on the client side, and frameworks like Twitter’s Finagle (with thier seminal function over a server essay) caused and is continuing to cause on the backend.
Another chunk of good news is that we’re going to go over a pragmatic approach to functional programming that produces a good amount of the value but not all of it, and that in turn, it won’t take nearly as much time to learn. Some FP purists would say this is heresy, but we’ll continue any way.
To keep our pragmatic approach, we’ll look at two tools I’ve built in Python that are open source and exhibit this kind of functional programming approach.
Suppose you have a ~/.dotfiles folder (as I do), which you carry over from machine to machine, and it includes your set up files, infrastructure, configuration, software lists to install and so on.
How could we make it so that a machine can be provisioned automatically without resorting to big hammers like Ansible or Chef? The answer I found is that with an opinionated folder structure and a couple of tools (dotlinker, dotrunner), this was completely possible, maintainable and reliable.
We start with an opinionated structure for our ~/.dotfiles folder. Here's part of mine as it stands right now:
├── fish
│ └── .config
│ └── fish
│ ├── config.fish.symlink
│ └── fishfile.symlink
├── node
│ ├── install.sh
│ ├── install.yml
│ └── node.sh
├── osx
│ ├── install.sh
│ └── install.yml
├── python
│ ├── install.sh
│ └── install.ymlWe want to accomplish two things:
- Go over all
**/*/.symlinkfiles with their hierarchy and set them up as symlinks. So transform~/.dotfiles/fish/.config/fish/config.fish.symlinkto~/.config/fish/config.fishand symlink based on that. - Build a DAG (Directed Acyclic Graph) of all of the install tasks (here: node, osx, python) by scanning, looking for, and parsing
install.ymls, also assuming that they depend on one another so execute them in an efficient, dependent-free, way.
If we started from scratch, here’s how we’d build these pieces of software, in a functional programming mindset.
Identify the Pipeline
Unless we’re building UI — and that also is arguable — which means we have to keep state and maintain a state machine at all times, we’re at a big advantage — we should be dealing with problems that should map to having a bunch of data go through a bunch of functions in a forward-only way.
That means, that as you approach a problem — you can assume, and look for, the pipeline that should exist.
In our case, for the symlinker part we can assume the following pipeline:
- Get to a position where we list all files under
.dotfiles - Sort them out, filter unneeded
- Build a linking map of who’s source and where’s target
- Side effect time! validate that targets don’t exist
- Side effect time! execute all os-level symlink calls on source and target
So in concept — a bunch of files moving through a bunch of functions. Check! That’s the north star that should guide our implementation.
We say that our data moves though our functions, which is important. And if we look at a drawing, we imagine it that way:
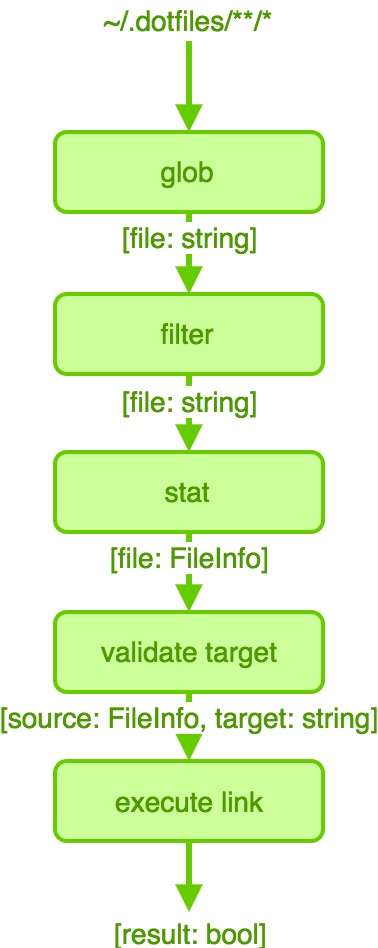
Where the notation:
[file: string]Means an array of files, of type string, and [result: bool] would be an array of results of type bool and so on. Most important to note is how types expand and contract, or map and reduce along the pipeline:
string
| \
string (filtered strings)
| \
FileInfo (filesystem 'stat' turned every string into a FileInfo)
| \
(FileInfo, string) (we paired target and source, ready for action)
| /
| /
bool (mindlessly linked source and target, resulted in true/false per pair)Let’s break down how we can use toolz to implement this:
from toolz.curried import pipe, filter, map, concat, complement
from os.path import splitext
def reject(pred):
return filter(complement(pred))
pipe(io.ls(root),
filter(io.isdir),
reject(lambda d: d.startswith('-')),
map(io.glob),
concat,
filter(lambda f: splitext(f)[1] == '.symlink'),
map(io.stat),
map(lambda info: (info, make_target_of(info))),
map(io.link),
list)Build a Pipe with pipe
Start your flow with pipe. A pipe backed by pipe means "give me a list of things" (io.ls(root)) to start out with, and then a list of functions to thread this data into.
Some languages take this so seriously, that they have their own operator for pipe:
|>There’s a Function for It
Use functional operators (e.g. map, filter and so on). A map(io.glob) captures an otherwise painfully written for-each-loop, and it clearly states what you want do - and not how you want to do it - glob over all entries coming from ls. And it took the minimum number of characters to write that's still legible.
Currying Matters
Use the curried form of functional operators. This allows us to build concise execution units that are reusable: a map(io.glob) builds a new function that takes a list of things and it sits there waiting for those things to arrive. This means you can reuse it anywhere you want, pass it, cache it, and most importantly - compose it. The opposite is to map(io.glob, <list of things>) which forces you to give an input at the point of declaration, and is impossible to compose (for example, you can't use it in a pipe).
More over, turning into point-free style (there is a more pure definition for ‘point-free’ which we’ll ignore) by making use of currying, we can have this:
reject(lambda d: d.startswith('-')),Become this:
prefixed_by = lambda pref: lambda d: d.startswith(pref)
reject(prefixed_by('-')),Essentially turning startswith which is a method that must be bound to an existing instance of string to an independent function called prefixed_by. This makes the reject clause clearer.
Generally, we can keep doing this to produce a “cleaner” version of our pipeline, having to extract and define more of these kinds of generic utility functions:
from toolz.curried import pipe, filter, map, mapcat, complement
from os.path import splitext
reject = lambda pred: filter(complement(pred))
prefixed_by = lambda pref: lambda d: d.startswith(pref)
just_symlinks = lambda f: splitext(f)[1] == '.symlink'
make_targets = lambda info: (info, make_target_of(info))
pipe(io.ls(root),
filter(io.isdir)
reject(prefixed_by('-')),
mapcat(io.glob),
filter(just_symlinks),
map(io.stat),
map(make_targets),
map(io.link)
list)I hope that with this I’ve inspired you to do more, and if you feel willing take a look at the toolz API, and its Streaming Analytics use case.
The next place to visit is the awesome functional python list. There you’ll find libraries such as toolz, pydash, funcy, and more, and functional languages with a strong resemblence to Python, or implemented with Python like Hy and Coconut.
Hexagonal Architecture and Functional Programming
A pattern I’ve started to use around ten years ago, when I was strongly into Domain Driven Design (while doing enterprise C# and Java), is hexagonal architecture — also known as “Onion Architecture”, and later known as “Clean Architecture”. The reason all these popped up at that tight corridor of time (2008–10) is “Web scale”; the growing demand for scalable and maintainable softare, and the massive shifts in how we saw databases and persistence layers to name a few.
While all these architecture concepts have had slightly different lines of thought, their theme is common: a core business logic, surrounded by plugins or adapters, or more commonly: interfaces.
I still adopt the same approach in functional programming. Specifically, when doing I/O or side-effects, I consolidate those into individual modules to be plugged onto the core.
pipe(io.ls(root),
filter(io.isdir)
reject(prefixed_by('-')),
mapcat(io.glob),
filter(just_symlinks),
map(io.stat),
map(make_targets),
map(io.link)
list)In the code listings above we saw one such module as the io module. It's responsible for all of the I/O access in that codebase and even though it might sound like being a control-freak over I/O is tiresome - it's worth it. It's worth it in cleanliness, in testing, and in helping drive a better design overall.
Some pure languages such as Haskell go to great length to model I/O (or more generally: side effects) in a perfect way (you might have heard the term “Monad” some time), but I’ve tactically chosen to sidestep that topic. What’s more, is that not all functional programming languages choose to be pure, a notable one which I tend to like is OCaml and its more hipster, Javascript backed, sibling ReasonML from Facebook.
Exceptions and Error Handling
We left out a topic that needs a good chunk of theory and mind-massaging before acknowledging it’s a better way to do things: error handling in functional programming. Exceptions and similar errors shatter the stack, and break the program flow — how does that sit with the concept of data always flowing forward onto functions in functional programming?
The answer is that there are no exceptions. There’s errors, and more abstractly there’s probably two kinds of return types from any function: success and failure.
That means that in this ideal model, every function in the functional programming world receives and outputs a result type that can shape as two different types: success and failure. Let’s model this in the following fictional statically typed functional language:
fun foo() -> Result<Success(x), Failure(y)>
main(){
match(foo()){
Success(x): println(x)
Failure(y): error(y)
}
}The -> Result notation means "returns a type of Result" and the Result<Success(x),Failure(y)> notation means Result can generically represent Success or Failure each of which can contain a value x or y which we can extract later with match.
match is a common operator in typed functional languages (also in untyped ones but much more effective in typed languages) that help us perform introspection on a type, branch according to the specific type, and destructure it - extract its content and bind its content to a normal value variable - all at once(!).
At this moment foo is receiving no argument, but if it would - according to the theory we're developing here - it would get the same "carrier" type: Result.
fun foo(Result) -> Result<Success(x), Failure(y)>
main(){
some_result = ...
match(foo(some_result)){
Success(x): println(x)
Failure(y): error(y)
}
}Now comes the fun part. What if some_result is actually an error result - or in other words, in an error state? Surely, we don't want foo to do any redundant work. In this case want it to short-circuit and return the result it's passed as input (because it's an error).
Threading the error forward in such a way, is the start of replacing the traditional error handling mechanism we might have thought was the only one in the world — exceptions.
Actually you already might have implemented such a thing — all I need in order to make you remember it is throw a curve ball at you. Here’s a question — if you had a list of background jobs to spin off, each job to be performed by a different thread — did you use exceptions to communicate errors? What did you do?
Hopefully, you’ve made each thread return a result — a success or an error. Finally arriving at a list of thread results:
[true, true, false, false, true]In this case, if you followed that kind of solution — you implicitly had the notion of a Result<true,false>. If this solution was good for this specific scenario, why not apply it to all scenarios. And more importantly, why have two ways to solve errors? (both exceptions and errors as result types). That's part of the everlasting discussions about why exceptions are a bad smell; there's no clear winner but now you get to have a good footing in this discussion.
As a side note: in our code listings so far, we didn’t explicitely model any of that error handling mechanism. That is because for dynamic languages this kind of construct is easier to implement (just a dict with a field indicating success or failure and a payload field as a result), but also very noisy to code (no pattern matching means if’s and tiresome manual left-right-coding). So we kept it out for now.
Special thanks for reviewing: Magnus Therning, Ofer Horowitz
